

VRay渲染守则&(DMC核心采样管理器及其早期终止机制)
一、VRay渲染守则
1.永远不要使用材质的opacity属性,也不要在opacity通道中贴图来实现半透明效果或制作某种贴片效果,比如片树。原因:VRay的IRmap采样点根本不能很好的支持opacity属性,特别在动画的情况下,一旦物体发生位置改变,采样点对位分析的过程在遇到opacity通道的情况时将异常的慢。
2.尽可能使用纯32位Raw格式来保存图像或图像序列,因为这能为后期带来质的调整变化,请注意,从帧缓存窗口中保存的图像每通道最多只能是8位的,不可能是32位图像。要输出纯32位Raw格式应该在VRay Fram Buffer面板中,通过输出raw序列的功能完成。
3.最好用算好的lightcache灯光缓冲文件来计算材质的模糊反折射,而不是直接计算,因为lc能大大简化模糊反折射计算过程,理由很简单,LC是反向光线追踪,节省了大量反射或折射计算开销。
4. 请小心调整QMC或DMC核心管理面板的内容,所有调用QMC分布式光线追踪的过程或者说功能块,都受这个面板参数的影响,比如DMC sampler反走样,IRmap的半球光线收集过程,面灯的阴影采样、模糊反折射的非插值计算等等。
5. 如果调整了DMC核心管理器里面的noise threshold或adaptive amount参数,是需要重新跑光渲irmap才有效果的,不能重用。

6. 动画闪烁产生的原因并不总是一样的,要分清楚是什么类型的,如果是大块光斑或黑斑的跳闪,基本上是由于Irmap采样点不足,这种情况容易发生在摄像机较远处,因为那里的相对像素区域小,采样点投在那的机率更低,需要手动补采样点,另一种闪烁的类型是,模糊反折射的表面和面光源阴影区域点闪,这是因为QMC分布光线不足以及过早的QMC早期终止,如果提高subdivision还没明显效果,那么就要动用QMC的核心管理器了,降低noise threshold和adaptive amount,直到动画的点闪在你承受范围内,但代价是巨大的。还有一种比较常见的闪烁,远处极高频图像的闪烁,比如密集的线条,密集的交错贴图,这些在极远处容易产生摩尔纹或频闪,提高基本反走样是唯一解决办法,而选择合适的过滤器则可使时间代价相对降低。闪烁对于一个像Vray这样非工业级的渲染器,基本是很常见的,在这方面不能指望过于完美,完全去除噪点或点闪可能需要极高的反走样或分布式光线数量。
7. 如果你的场景非常大,常规情况下一渲就跳出,可以肯定是内存问题,默认情况下VRay是自动采用内存分配方式,绝大部分场景都是分配的静态内存,而代理物体和VRay fur物体总是使用动态内存,动态内存的好处是自由且自动分配,它会在需要时分配不需要时释放,我们可以将渲染方式强制为动态类型,也就是dynamic类型,这样,渲染速度会变慢,但有可能帮你渲出这个场景来。
8. 尽可能不要使用color mapping中除线性外的其他方式,它将导致分层渲染无法还原,因为这是个有损过程。
9. VRay材质的高光范围和反射的模糊反射范围默认是锁定的,当然你可以解开单独来调节,但高光的强度永远和反射强度是锁定的,如果你希望仅有强烈的高光但又不希望看到强烈的反射,请在材质选项里将tace reflection去掉即可。
二、DMC核心采样管理器及其早期终止机制:
VRay是一个典型的以MC分布式光线追踪为核心的渲染器,我们在渲染过程中经常会面对很多不同类型的计算过程,其中很多都离不开MC分布式光线追踪。下面我列出需要调用MC分布式光线追踪过程的特性和子功能块:
1:Fixed类型的图像反走样器(当其取值大于1时,会调用MC分布式过程来对每像素进行反走样。)
2: Adaptive DMC sampler类型的图像反走样器(老版本叫Adaptive QMC sampler,它和fixed类型唯一的区别是带有自适应过程)。
3:VRay Mtl材质中的模糊反射和模糊折射特性的计算(当你将VRay Mtl中的Reflection面板或Refraction面板里的Glossy值调为任何小于1的值时,即打开了Glossyeffect(模糊特性)计算的过程,这个过程将调用MC分布式过程。)
4:VRay Dirt Map 贴图的计算过程(也就是我们常说的VRay的AO,这一过程需要调用MC分布式光线追踪来发射大量探测光线去收集每个像素周围的阻塞情况。)
5:Vray面光源的软阴影计算过程(与传统的光线追踪投下的生硬阴影边缘不同,VRay的面光靠MC分布式光线追踪发射的次级光线来摸拟出面光源应有的阴影虚化效果。)
6: VRay的运动模糊特性(运动模糊的计算依靠的是分布式光线追踪算法对时间域的离散计算,所以这个过程完全依赖MC分布式过程。)
7:VRay的摄像机景深特效(景深的实现依靠的是分布式光线追踪对空间距离的离散计算。)
8:IrradianceMap的计算过程 (在IRmap的计算过程中,当通过prepass分析图像并放下采样点后,需要从采样点向周围环境的虚拟半球空间发射分布式光线以探测和收集信息,从而计算出采样点本身像素的最终GI结果,这个过程也就是调用MC分布式光线追踪来完成的,而Hsph subdivs决定的其实就是这个过程中发射半球分布式光线的数量。)
9:Brute force算法计算GI的过程 (Brute force即老版本的QMC GI算法,无论你在VRay间接照明面板的主GI引擎还是次级GI引擎中打开Brute force,都是直接调用MC分布式过程对图像上每一个像素进行GI计算) 根据上表中列出的主要依靠MC分布式过程的特性,我们不难看出MC分布式光线追踪算法在VRay中的主导性地位,那么,请大家至少记住上表中我所提到的这几种情况,因为它们的计算过程都和下面我要讲的这个面板里提供的参数有关,那就是VRay DMC sampler (VRay DMC核心采样管理器)。 原来这个面板的名字叫“VRay QMC sampler”,VRay从1.5版开始更名为"DM C",这里很多朋友对此都有不解,到底DMC与QMC的区别在哪里?有没有区别,提及于此,我先为大家理清楚几个概念:
首先,理解一下MC,也就是Monte Carlo(蒙特卡罗),蒙特卡罗其实是一种分布式积分,而蒙特卡罗算法专门用这种积分所产生的分布概率来产生各种模糊数据,其实上表所涉及的特性都是为了解决模糊效果,反走样其实就是为了将图像锯齿模糊化,模糊反折射也是为了产生模糊但有源于真实情况的反折射成像,运动模糊其实就是为了让成像根据运动速度与时间的关系产生出模糊效果,诸如此类。
而什么又是QMC呢?全名是Quasi-Monte Carlo(准蒙特卡罗),这其实是纯蒙特卡罗算法的一个变种,它缩减了算法取样的范围,QMC所产生的随机样本全部来自于一个低差异数据序列,而不是传统MC的庞大假随机数生成,但事实上,VRay在新版本中已经摒弃了QMC分布式特性,使用一种全新的MC变种算法,也就是接下来我们要说的DMC。
DMC的全称为:Deterministic Monte Carlo(确定性蒙特卡罗),DMC作为MC的一个变种,其区别在于,MC生成用于模糊结果的采样点情况源于一个庞大的随机数据集,即使我们计算的情况或考虑的内容本身根本没有发生改变,但计算的模糊结果每一次都是不一样的。DMC则不同,DMC先依据某种规则考虑计算的重要性和内容的特质,然后事先确定一组数据序列,而样本则产生于这组已确定的数据序列,因此,多次的计算结果是一致的,这有利于动画的计算,以及更好的降低可能带来的噪点情况,DMC和QMC之间的区别在于,这两者选择产生样本的数据序列集不同,考虑规则不同。事实上,QMC只是DMC的一个子集。
OK,我们不需要在这些纯理论定义上浪费太多时间,点明一下就行,我着重要阐述的,是VRay的这个核心DMC,是如何影响上表中这些功能实现的。
先来看看下面这个面板,这就是VRay DMC sampler,VRay的核心。
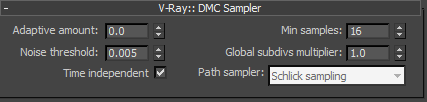
首先理解,我们常说的分布式光线数量,其实就是分布式光线追踪的samples样本数,这是一个概念。
我们所见到的和分布式光线追踪有关的subdivis参数和样本数的关系是平方关系,也就是说,subdivis值的平方就是分布式光线数量(或样本数量)。
VRay的DMC分布式光线追踪算法最终产生多少samples样本来得到一个模糊结果,取决于三个方面。
一方面取决于每个局部效果或功能块,我们用户指定了多少subdivs值,大家都知道上表中我列出的各个特性其面板里都有subdivis参数,那么这个参数是一个非常重要的基本决定性因素,事实上用户指定的每个功能部分的subdivis最终都要乘以面板中的Global subdivs multiplier这个倍增器。
一方面,还取决于VRay的重要性采样分析,这是一个自适应判断过程,虽然用户为每一个特性指定了subdivis值来确定其应有样本数量,但事实上VRay认为它先要通过一个自适应过程判断一下待计算模糊效果的像素点(shade point)是否是一个重要性采样,这个规则很复杂,我不详细说明,比如暗的像素会比亮的像素需要更少的细节,比如远的会比近的需要更少的模糊细节,诸如此类,这个自适应判断过程的作用是要不要对这个像素使用全部的用户所指定的subdivis数量级别来生成分布式光线样本,如果某像素点实际上是比较远或暗的像素,VRay认为用某个低于用户指定的subdivs值即可,越不重要的像素点就用越低于指定subdivs的值来生成样本。相反,相对重要的就用接近用户指定的subdivis值来产生样本。然而,用户可以指定VRay重要性自适应分析对最终形成样本起改变作用的权重,面板上看到的Adaptive amount值就是这个权重参数,当这个值为1时,VRay将完全参考重要性分析的过程来决定如何优化(其实就是降低)用户指定的subdivs参数对某个像素点的影响,用户给定的subdivs值此时只是个理想状态,几乎完全要被这个重要性自适应判断过程所削减,降低Adaptive amount这个权重,将使这个自适应过程改变用户决定权的情况降低,当降到零时,完全使用用户给定的subdivs值产生某像素点的样本,即理想状态。
最后,我们把经由第一个方面,和第二个方面后最终决定的样本数量叫做VRay分布式额定样本数量。后面它还将受到早期终止机制影响。
最后一个方面,除了受用户指定的subdivis值,以及重要性自适应分析,还受一个机制影响,那就是早期终止机制,在不停产生分布式光线数量样本以计算模糊效果的过程中,VRay会不停判断正在生成的模糊结果其噪点是否已经在承受范围内,如果达到承受范转,或者说达标,那么不管前两个方面所提到的因素最终确定了用多少样本来生成结果,即使目前并未分布够那个确定的样本数量,也立即停止,停止前完成min sapmles参数指定的最小样本生成数量。而这个判断噪点的标准,就是我们看到的面板中的noise threshold参数,这个参数越小,VRay对模糊结果的噪声敏感程度就越高,VRay所能容忍的噪点情况就越小,相反对质量要求就越高,早期终止将越晚出现,甚至完全不出现。反之,noise threshold参数越大,VRay对模糊结果的噪声敏感程度就越低,所能容忍的噪点情况就越大,质量要求越低,早期终止容易越早出现。
说了这么多理论且抽象的东西,为了帮助大家理解,我举个例子:
以模糊反射为例,某VRay材质我设置Reflection glossy为0.65,这时其实就打开了模糊反射的计算,并且下面的subdivs值我给16(默认为8),换算过来就是应该产生16*16=256条分布式光线,或者说256样本数,即被赋材质的物体表面的每个像素点(shade point)将用256个样本光线来计算其模糊后效果,但这时情况并没这么简单,先分析该shade点是不是应该属于重要性采样,假定这个像素很远,也很暗,VRay认为并不那么重要,于是说,用什么256个样本来采样,100个够了,但VRay 说的100个和用户指定的256个谁更说了算,用Adaptive amount权重来决定 ,当Adaptive amount为1时,Vray自适应重要性分析将占据一半的权重,即最终的样本数将为用户指定的256和VRay认为的100的平均值,即178,如果为0,则完全按用户指定的256个样本算,不考虑重要性分析,如果介于两者之间,比如Adaptive amount默认为0.85,那么将按:
(VRay认为的样本数*adaptive amount+用户指定的样本数*(2-adaptive amount))/2这个公式来计算。
即:(100*0.85+256*(2-0.85))/2=190 ,也就是说这时用户占百分之115的权重,VRay分析的占百分之85的权重,一共是百分之两百权重。这时实际以190个样本数来生成该像素反射模糊效果。
最后,我把一些特殊情况拿出来单独说明一下:
Fixed图像反走样模式情况下,由于该反走样根本没有自适应过程,除了subdivs值受最终要乘以DMC sampler面板里的Global subdivs multiplier外,不受其它任何参数影响。
Adaptive DMC Sampler图像反走样模式下,DMC核心面板里的min samples参数无意义,完全由Adaptive DMC Sampler图像反走样自身的min subdivs参数决定最小样本数量。当Adatpive DMC Sample反走样面板中的use DMC sampler threshold被勾掉后,DMC核心管理器的重要性自适应判断不再影响该图像反走样过程,而由它自带的clr threshold颜色阀值来简单控制其自适应判断,但早期终止机制仍然作用于该反走样过程,noise threshold仍然有效。
更多图文教程推荐:









评论(0)